← Back to Projects
Build an e2e RAG System
CompletedFebruary 2026
Build AI knowledge-worker using RAG to become an expert on all company-related matters. The knowledge is a set of markdown documents chunked, indexed for retrieval as part of the RAG pipeline.
Key Concepts:
- LangChain Text Splitters to create document chunks, experimenting with different chunking strategies including TextRecursive, Markdown and Semantic Chunking and Hierarchical Chunking
- HuggingFaceEmbeddings and OpenAIEmbeddings as embedding models
- Chroma for vector store for quick retrieval. Preferred to use an open-source vs paid versions such as pinecone or Weaviate
- Build a RAG Pipeline using LangChain for Retriever abstraction on Chroma vector store
- Evaluation of the RAG system components with UI for performance visualization
- Creation of ground truth questions/answers (ground truth) in JSONL format
- Measuring Retrieval (MRR, nDCG, Keyword match, Recall@K, Precision@K)
- Measuring Generation with LLM-as-judge
- Query Rewriting & Expansion before Retrieval
- Re-ranking by using LLM to sub-select from RAG results
- Graph RAG to retrieve content closely related to similar documents
- Agentic RAG using Agents for retrieval, combining with memory and tools such as SQL
Pipeline Components:
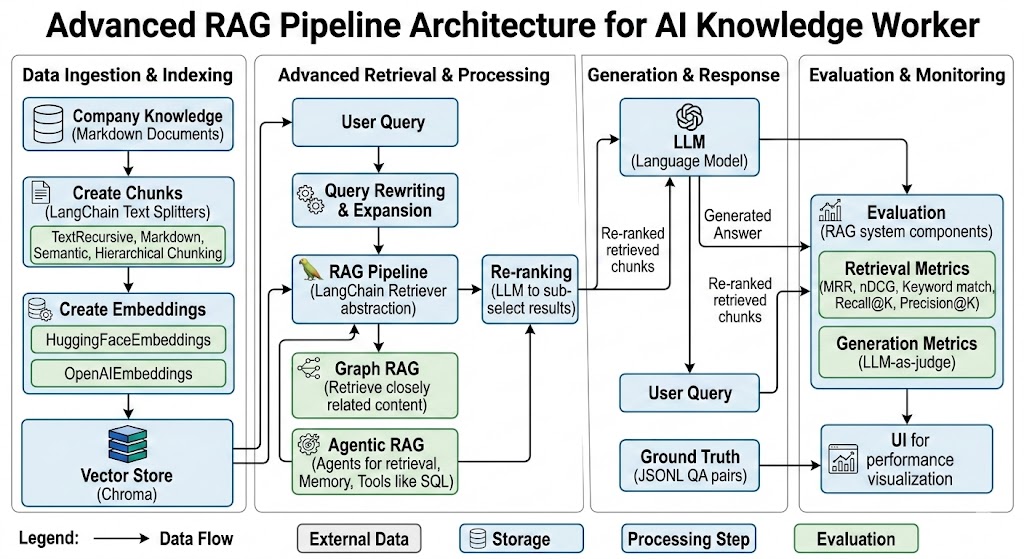
- Create Chunks
- Create embeddings
- Add Query rewriting
- Add Query Expansion
- Retrieve Context
- Re-rank retrieved chunks
RAGGraphRAGAgenticRAGLangChainEvalsLLM-as-a-JudgeMRRNDCGVector StoreEmbeddingsPython